概述
记忆是一种能够记住先前交互信息的系统。对于人工智能代理而言,记忆至关重要,因为它使代理能够记住之前的交互、从反馈中学习并适应用户的偏好。随着代理处理的任务越来越复杂,涉及的用户交互越来越多,这种能力对于提高效率和用户满意度变得至关重要。 短期记忆使您的应用程序能够在单个线程或对话中记住之前的交互。线程用于组织一次会话中的多个交互,类似于电子邮件将消息分组到单个对话中的方式。
使用方法
要为代理添加短期记忆(线程级持久化),您需要在创建代理时指定一个checkpointer。
LangChain 的代理将短期记忆作为代理状态的一部分进行管理。通过将这些状态存储在图的状态中,代理可以访问给定对话的完整上下文,同时保持不同线程之间的隔离。状态通过 checkpointer 持久化到数据库(或内存)中,以便随时恢复线程。短期记忆在代理被调用或完成一个步骤(如工具调用)时更新,并在每个步骤开始时读取状态。
在生产环境中
在生产环境中,请使用由数据库支持的 checkpointer:自定义代理记忆
默认情况下,代理使用AgentState 来管理短期记忆,特别是通过 messages 键管理对话历史。
用户可以通过继承 AgentState 来向状态添加额外字段。
这种自定义状态随后可以通过工具和动态提示/模型函数访问。
常见模式
启用短期记忆后,长对话可能会超出LLM的上下文窗口。常见的解决方案包括:裁剪消息
删除前N条或后N条消息(在调用LLM之前)
删除消息
从LangGraph状态中永久删除消息
总结消息
总结历史中的早期消息并用摘要替换它们
自定义策略
自定义策略(例如,消息过滤等)
裁剪消息
大多数LLM都有最大支持的上下文窗口(以token为单位)。 决定何时截断消息的一种方法是计算消息历史中的token数量,并在接近该限制时进行截断。如果您使用的是LangChain,可以使用裁剪消息工具并指定要保留的token数量,以及用于处理边界的strategy(例如,保留最后 maxTokens)。
要在代理中裁剪消息历史,请使用 @[pre_model_hook][create_agent] 和 trim_messages 函数:
删除消息
您可以从图状态中删除消息以管理消息历史。 当您想要删除特定消息或清除整个消息历史时,这非常有用。 要从图状态中删除消息,可以使用RemoveMessage。
为了使 RemoveMessage 正常工作,您需要使用带有 add_messages reducer 的状态键。
默认的 AgentState 提供了这一点。
要删除特定消息:
总结消息
如上所述,裁剪或删除消息的问题在于,您可能会因消息队列的削减而丢失信息。 因此,一些应用受益于使用聊天模型对消息历史进行更复杂的摘要处理方法。 要在代理中总结消息历史,请使用 @[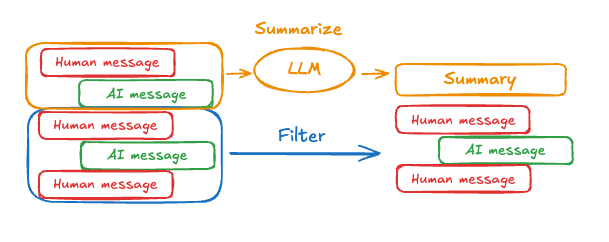{kind=link}
pre_model_hook][create_agent] 和预构建的 SummarizationNode 抽象:
访问
您可以通过以下几种不同方式访问代理的短期记忆:工具
在工具中读取短期记忆
通过在工具签名中使用InjectedState 注解将代理的状态注入工具签名,从而在工具中访问短期记忆(状态)。
此注解会将状态从工具签名中隐藏(因此模型看不到它),但工具可以访问它。
从工具中写入短期记忆
要在执行过程中修改代理的短期记忆(状态),您可以直接从工具中返回状态更新。 这对于持久化中间结果或使信息可供后续工具或提示访问非常有用。提示
通过将代理的状态注入提示函数签名,在动态提示函数中访问短期记忆(状态)。输出