- 获取并预处理用于检索的文档。
- 为这些文档建立索引以支持语义搜索,并为代理创建一个检索器工具。
- 构建一个代理式 RAG 系统,能够自主决定何时使用检索器工具。
{kind=link}
设置
让我们先下载所需的包并设置 API 密钥:%%capture --no-stderr
%pip install -U --quiet langgraph "langchain[openai]" langchain-community langchain-text-splitters
import getpass
import os
def _set_env(key: str):
if key not in os.environ:
os.environ[key] = getpass.getpass(f"{key}:")
_set_env("OPENAI_API_KEY")
注册 LangSmith,可快速发现并提升您的 LangGraph 项目性能。LangSmith 允许您使用跟踪数据来调试、测试和监控基于 LangGraph 构建的 LLM 应用。
1. 预处理文档
- 获取将在我们的 RAG 系统中使用的文档。我们将使用 Lilian Weng 的优秀博客 中最近的三篇文章。首先,使用
WebBaseLoader工具获取页面内容:
from langchain_community.document_loaders import WebBaseLoader
urls = [
"https://lilianweng.github.io/posts/2024-11-28-reward-hacking/",
"https://lilianweng.github.io/posts/2024-07-07-hallucination/",
"https://lilianweng.github.io/posts/2024-04-12-diffusion-video/",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs[0][0].page_content.strip()[:1000]
- 将获取的文档分割成更小的块,以便索引到我们的向量存储中:
from langchain_text_splitters import RecursiveCharacterTextSplitter
docs_list = [item for sublist in docs for item in sublist]
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=100, chunk_overlap=50
)
doc_splits = text_splitter.split_documents(docs_list)
doc_splits[0].page_content.strip()
2. 创建检索器工具
现在我们有了分割好的文档,可以将它们索引到一个用于语义搜索的向量存储中。- 使用内存中的向量存储和 OpenAI 嵌入:
from langchain_core.vectorstores import InMemoryVectorStore
from langchain_openai import OpenAIEmbeddings
vectorstore = InMemoryVectorStore.from_documents(
documents=doc_splits, embedding=OpenAIEmbeddings()
)
retriever = vectorstore.as_retriever()
- 使用 LangChain 预构建的
create_retriever_tool创建一个检索器工具:
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"retrieve_blog_posts",
"搜索并返回有关 Lilian Weng 博客文章的信息。",
)
- 测试该工具:
retriever_tool.invoke({"query": "奖励破解的类型"})
3. 生成查询
现在我们将开始构建代理式 RAG 图的组件(节点 和 边)。 请注意,这些组件将在MessagesState 上操作——该图状态包含一个带有聊天消息列表的 messages 键。
- 构建
generate_query_or_respond节点。它将调用一个 LLM,根据当前图状态(消息列表)生成响应。根据输入消息,它将决定是使用检索器工具进行检索,还是直接回应用户。注意,我们通过.bind_tools让聊天模型访问我们之前创建的retriever_tool:
from langgraph.graph import MessagesState
from langchain.chat_models import init_chat_model
response_model = init_chat_model("openai:gpt-4.1", temperature=0)
def generate_query_or_respond(state: MessagesState):
"""根据当前状态调用模型生成响应。根据问题,
它将决定使用检索器工具进行检索,或直接回应用户。
"""
response = (
response_model
.bind_tools([retriever_tool]).invoke(state["messages"])
)
return {"messages": [response]}
- 在随机输入上尝试:
input = {"messages": [{"role": "user", "content": "hello!"}]}
generate_query_or_respond(input)["messages"][-1].pretty_print()
================================== AI 消息 ==================================
你好!今天有什么我可以帮你的吗?
- 问一个需要语义搜索的问题:
input = {
"messages": [
{
"role": "user",
"content": "Lilian Weng 对奖励破解的类型有什么看法?",
}
]
}
generate_query_or_respond(input)["messages"][-1].pretty_print()
================================== AI 消息 ==================================
工具调用:
retrieve_blog_posts (call_tYQxgfIlnQUDMdtAhdbXNwIM)
调用 ID: call_tYQxgfIlnQUDMdtAhdbXNwIM
参数:
query: 奖励破解的类型
4. 评估文档
- 添加一个条件边 —
grade_documents— 以确定检索到的文档是否与问题相关。我们将使用具有结构化输出模式GradeDocuments的模型进行文档评分。grade_documents函数将根据评分决策返回要前往的节点名称(generate_answer或rewrite_question):
from pydantic import BaseModel, Field
from typing import Literal
GRADE_PROMPT = (
"你是一个评估者,负责评估检索到的文档与用户问题的相关性。 \n "
"以下是检索到的文档: \n\n {context} \n\n"
"以下是用户问题: {question} \n"
"如果文档包含与用户问题相关的关键词或语义含义,则将其评为相关。 \n"
"给出二元评分 'yes' 或 'no',以表明文档是否与问题相关。"
)
class GradeDocuments(BaseModel):
"""使用二元评分对文档进行相关性检查。"""
binary_score: str = Field(
description="相关性评分:'yes' 表示相关,'no' 表示不相关"
)
grader_model = init_chat_model("openai:gpt-4.1", temperature=0)
def grade_documents(
state: MessagesState,
) -> Literal["generate_answer", "rewrite_question"]:
"""确定检索到的文档是否与问题相关。"""
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GRADE_PROMPT.format(question=question, context=context)
response = (
grader_model
.with_structured_output(GradeDocuments).invoke(
[{"role": "user", "content": prompt}]
)
)
score = response.binary_score
if score == "yes":
return "generate_answer"
else:
return "rewrite_question"
- 在工具响应中包含不相关文档的情况下运行:
from langchain_core.messages import convert_to_messages
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "Lilian Weng 对奖励破解的类型有什么看法?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_blog_posts",
"args": {"query": "奖励破解的类型"},
}
],
},
{"role": "tool", "content": "喵", "tool_call_id": "1"},
]
)
}
grade_documents(input)
- 确认相关文档被正确分类:
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "Lilian Weng 对奖励破解的类型有什么看法?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_blog_posts",
"args": {"query": "奖励破解的类型"},
}
],
},
{
"role": "tool",
"content": "奖励破解可分为两类:环境或目标设定错误,以及奖励篡改",
"tool_call_id": "1",
},
]
)
}
grade_documents(input)
5. 重写问题
- 构建
rewrite_question节点。检索器工具可能返回潜在的不相关文档,这表明需要改进原始用户问题。为此,我们将调用rewrite_question节点:
REWRITE_PROMPT = (
"查看输入并尝试推断其潜在的语义意图/含义。\n"
"以下是初始问题:"
"\n ------- \n"
"{question}"
"\n ------- \n"
"请提出一个改进后的问题:"
)
def rewrite_question(state: MessagesState):
"""重写原始用户问题。"""
messages = state["messages"]
question = messages[0].content
prompt = REWRITE_PROMPT.format(question=question)
response = response_model.invoke([{"role": "user", "content": prompt}])
return {"messages": [{"role": "user", "content": response.content}]}
- 尝试一下:
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "Lilian Weng 对奖励破解的类型有什么看法?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_blog_posts",
"args": {"query": "奖励破解的类型"},
}
],
},
{"role": "tool", "content": "喵", "tool_call_id": "1"},
]
)
}
response = rewrite_question(input)
print(response["messages"][-1]["content"])
Lilian Weng 描述了哪些不同类型的奖励破解?她是如何解释它们的?
6. 生成答案
- 构建
generate_answer节点:如果我们通过了评分检查,就可以根据原始问题和检索到的上下文生成最终答案:
GENERATE_PROMPT = (
"你是一个问答助手。 "
"使用以下检索到的上下文来回答问题。 "
"如果你不知道答案,就说你不知道。 "
"最多使用三句话,并保持答案简洁。\n"
"问题: {question} \n"
"上下文: {context}"
)
def generate_answer(state: MessagesState):
"""生成答案。"""
question = state["messages"][0].content
context = state["messages"][-1].content
prompt = GENERATE_PROMPT.format(question=question, context=context)
response = response_model.invoke([{"role": "user", "content": prompt}])
return {"messages": [response]}
- 试试看:
input = {
"messages": convert_to_messages(
[
{
"role": "user",
"content": "Lilian Weng 对奖励破解的类型有什么看法?",
},
{
"role": "assistant",
"content": "",
"tool_calls": [
{
"id": "1",
"name": "retrieve_blog_posts",
"args": {"query": "奖励破解的类型"},
}
],
},
{
"role": "tool",
"content": "奖励破解可分为两类:环境或目标设定错误,以及奖励篡改",
"tool_call_id": "1",
},
]
)
}
response = generate_answer(input)
response["messages"][-1].pretty_print()
================================== AI 消息 ==================================
Lilian Weng 将奖励破解分为两类:环境或目标设定错误,以及奖励篡改。她认为奖励破解是一个包含这两类的广泛概念。当代理利用奖励函数中的缺陷或歧义来获得高奖励,而没有执行预期行为时,就会发生奖励破解。
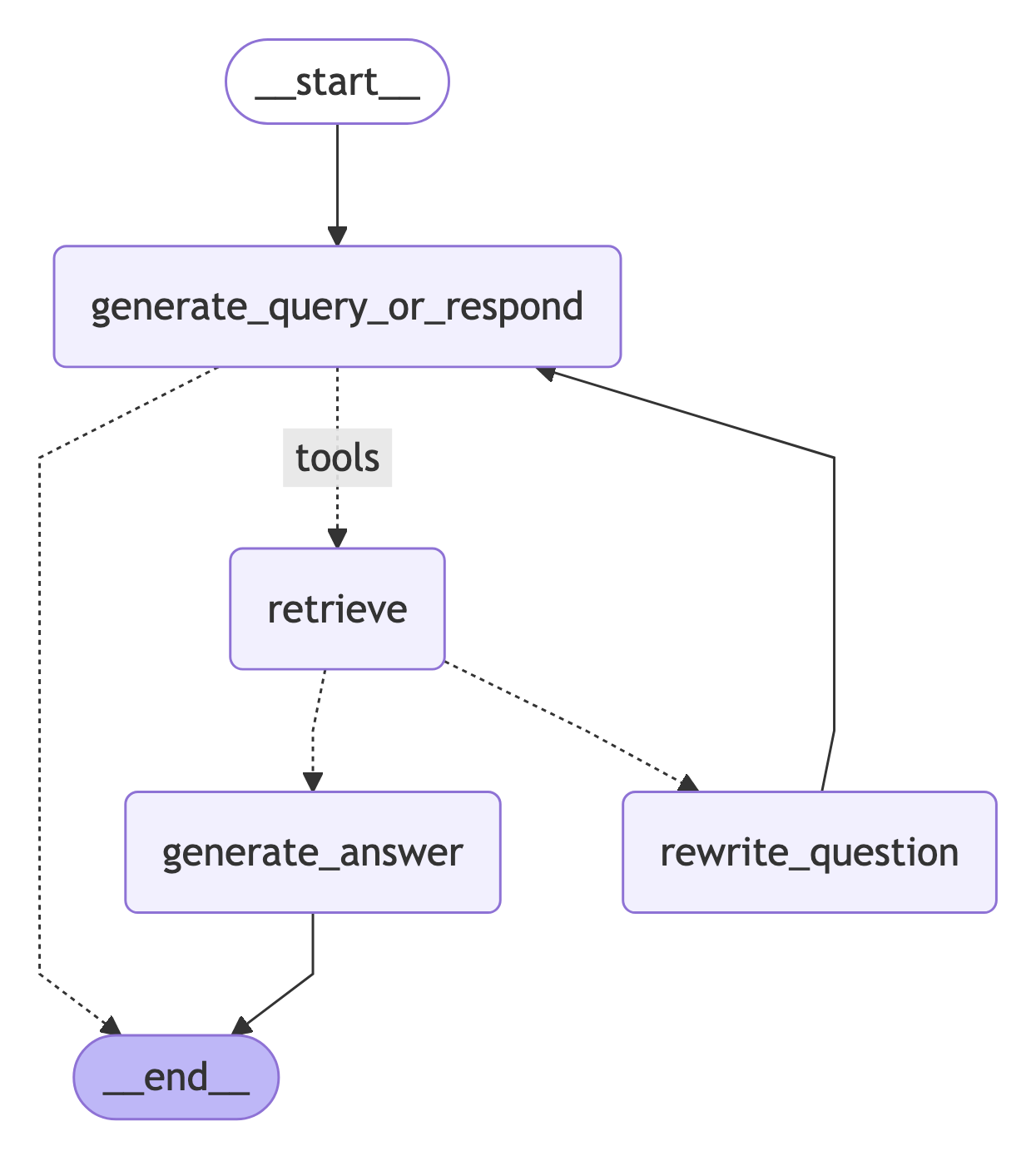
7. 组装图
- 从
generate_query_or_respond开始,确定是否需要调用retriever_tool - 使用
tools_condition路由到下一步:- 如果
generate_query_or_respond返回了tool_calls,则调用retriever_tool来检索上下文 - 否则,直接回应用户
- 如果
- 对检索到的文档内容进行相关性评分(
grade_documents),并路由到下一步:- 如果不相关,使用
rewrite_question重写问题,然后再次调用generate_query_or_respond - 如果相关,则进入
generate_answer,并使用包含检索文档上下文的ToolMessage生成最终响应
- 如果不相关,使用
from langgraph.graph import StateGraph, START, END
from langgraph.prebuilt import ToolNode
from langgraph.prebuilt import tools_condition
workflow = StateGraph(MessagesState)
# 定义我们将循环使用的节点
workflow.add_node(generate_query_or_respond)
workflow.add_node("retrieve", ToolNode([retriever_tool]))
workflow.add_node(rewrite_question)
workflow.add_node(generate_answer)
workflow.add_edge(START, "generate_query_or_respond")
# 决定是否检索
workflow.add_conditional_edges(
"generate_query_or_respond",
# 评估 LLM 的决策(调用 `retriever_tool` 工具或直接回应用户)
tools_condition,
{
# 将条件输出转换为我们图中的节点
"tools": "retrieve",
END: END,
},
)
# 在调用 `action` 节点后采取的边。
workflow.add_conditional_edges(
"retrieve",
# 评估代理决策
grade_documents,
)
workflow.add_edge("generate_answer", END)
workflow.add_edge("rewrite_question", "generate_query_or_respond")
# 编译
graph = workflow.compile()
from IPython.display import Image, display
display(Image(graph.get_graph().draw_mermaid_png()))
{kind=link}
8. 运行代理式 RAG
for chunk in graph.stream(
{
"messages": [
{
"role": "user",
"content": "Lilian Weng 对奖励破解的类型有什么看法?",
}
]
}
):
for node, update in chunk.items():
print("来自节点", node, "的更新")
update["messages"][-1].pretty_print()
print("\n\n")
来自节点 generate_query_or_respond 的更新
================================== AI 消息 ==================================
工具调用:
retrieve_blog_posts (call_NYu2vq4km9nNNEFqJwefWKu1)
调用 ID: call_NYu2vq4km9nNNEFqJwefWKu1
参数:
query: 奖励破解的类型
来自节点 retrieve 的更新
================================= 工具消息 ==================================
名称: retrieve_blog_posts
(注:一些工作将奖励篡改定义为与奖励破解不同的错位行为类别。但我在这里将奖励破解视为一个更广泛的概念。)
在高层次上,奖励破解可以分为两类:环境或目标设定错误,以及奖励篡改。
为什么奖励破解会发生?#
Pan 等人(2022)研究了奖励破解作为代理能力的函数,包括(1)模型大小,(2)动作空间分辨率,(3)观察空间噪声,和(4)训练时间。他们还提出了三种误设代理奖励的分类:
让我们定义奖励破解#
在强化学习中,奖励塑造具有挑战性。当强化学习代理利用奖励函数中的缺陷或歧义来获得高奖励,而没有真正学习预期行为或按设计完成任务时,就会发生奖励破解。近年来,提出了几个相关概念,都指某种形式的奖励破解:
来自节点 generate_answer 的更新
================================== AI 消息 ==================================
Lilian Weng 将奖励破解分为两类:环境或目标设定错误,以及奖励篡改。她认为奖励破解是一个包含这两类的广泛概念。当代理利用奖励函数中的缺陷或歧义来获得高奖励,而没有执行预期行为时,就会发生奖励破解。
设置
加载环境变量
在./examples 文件夹的根目录下添加一个包含您的变量的 .env 文件。
// import dotenv from 'dotenv';
// dotenv.config();
安装依赖
npm install cheerio zod zod-to-json-schema langchain @langchain/openai @langchain/core @langchain/community @langchain/textsplitters
检索器
import { CheerioWebBaseLoader } from "@langchain/community/document_loaders/web/cheerio";
import { RecursiveCharacterTextSplitter } from "@langchain/textsplitters";
import { MemoryVectorStore } from "langchain/vectorstores/memory";
import { OpenAIEmbeddings } from "@langchain/openai";
const urls = [
"https://lilianweng.github.io/posts/2023-06-23-agent/",
"https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/",
"https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/",
];
const docs = await Promise.all(
urls.map((url) => new CheerioWebBaseLoader(url).load()),
);
const docsList = docs.flat();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
const docSplits = await textSplitter.splitDocuments(docsList);
// 添加到向量数据库
const vectorStore = await MemoryVectorStore.fromDocuments(
docSplits,
new OpenAIEmbeddings(),
);
const retriever = vectorStore.asRetriever();
代理状态
我们将定义一个图。 您可以向图传递一个自定义的state 对象,或者使用一个简单的 messages 列表。
我们的状态将是一个 messages 列表。
图中的每个节点都会向其追加内容。
import { Annotation } from "@langchain/langgraph";
import { BaseMessage } from "@langchain/core/messages";
const GraphState = Annotation.Root({
messages: Annotation<BaseMessage[]>({
reducer: (x, y) => x.concat(y),
default: () => [],
})
})
import { createRetrieverTool } from "langchain/tools/retriever";
import { ToolNode } from "@langchain/langgraph/prebuilt";
const tool = createRetrieverTool(
retriever,
{
name: "retrieve_blog_posts",
description:
"搜索并返回有关 Lilian Weng 博客文章的信息,内容涉及 LLM 代理、提示工程和对 LLM 的对抗攻击。",
},
);
const tools = [tool];
const toolNode = new ToolNode<typeof GraphState.State>(tools);
节点和边
每个节点将 - 1/ 要么是一个函数,要么是一个可运行对象。 2/ 修改state。
边选择接下来调用哪个节点。
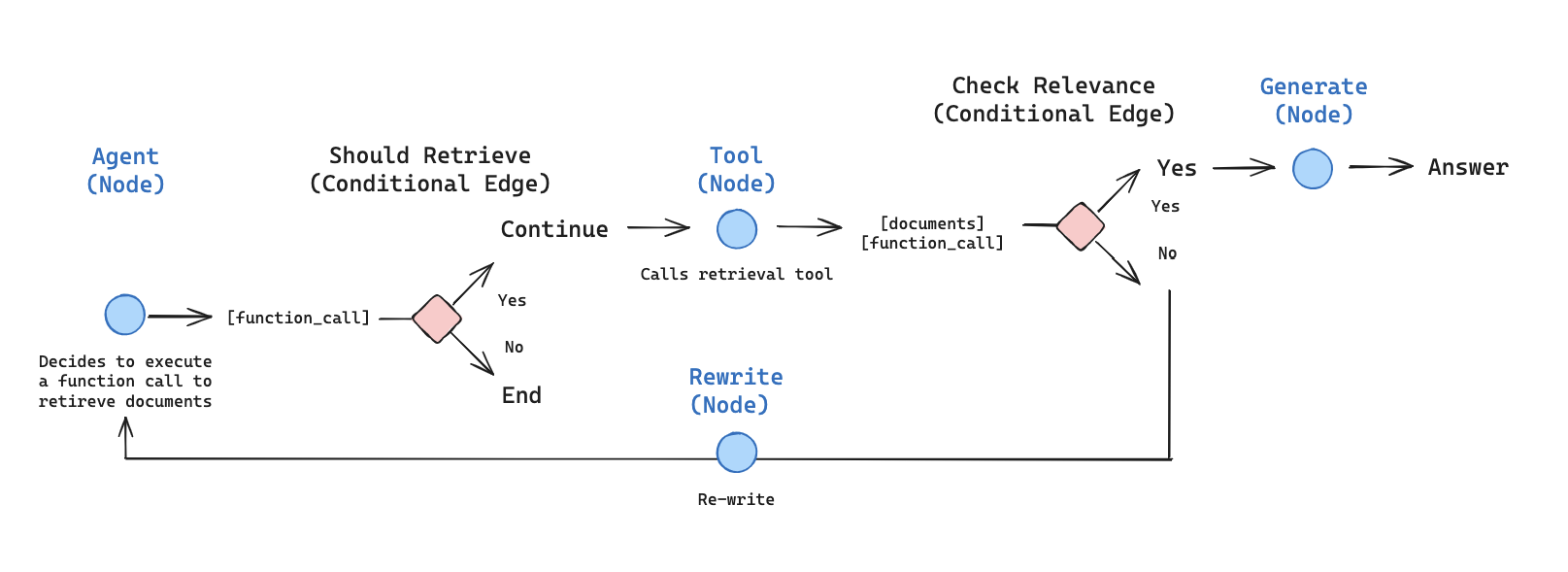
我们可以这样布局一个代理式 RAG 图:
混合式 RAG
边
import { END } from "@langchain/langgraph";
import { pull } from "langchain/hub";
import { z } from "zod";
import { ChatPromptTemplate } from "@langchain/core/prompts";
import { ChatOpenAI } from "@langchain/openai";
import { AIMessage, BaseMessage } from "@langchain/core/messages";
/**
* 决定代理是否应检索更多信息或结束流程。
* 此函数检查状态中的最后一条消息是否存在函数调用。如果存在工具调用,
* 则继续检索信息。否则,结束流程。
* @param {typeof GraphState.State} state - 代理的当前状态,包括所有消息。
* @returns {string} - 一个决定,以继续检索流程或结束它。
*/
function shouldRetrieve(state: typeof GraphState.State): string {
const { messages } = state;
console.log("---决定是否检索---");
const lastMessage = messages[messages.length - 1];
if ("tool_calls" in lastMessage && Array.isArray(lastMessage.tool_calls) && lastMessage.tool_calls.length) {
console.log("---决策:检索---");
return "retrieve";
}
// 如果没有工具调用,则结束。
return END;
}
/**
* 根据检索到的文档的相关性,确定代理是否应继续。
*
/**
* 根据检索到的文档与用户问题的相关性,判断代理是否应继续运行。
* 该函数检查对话中的最后一条消息是否为 FunctionMessage 类型,以表明已执行文档检索。
* 然后,它使用预定义的模型和输出解析器评估这些文档与用户初始问题的相关性。
* 如果文档相关,则认为对话已完成;否则,将继续执行检索过程。
* @param {typeof GraphState.State} state - 代理的当前状态,包含所有消息。
* @returns {Promise<Partial<typeof GraphState.State>>} - 更新后的状态,新消息已添加到消息列表中。
*/
async function gradeDocuments(state: typeof GraphState.State): Promise<Partial<typeof GraphState.State>> {
console.log("---获取相关性评分---");
const { messages } = state;
const tool = {
name: "give_relevance_score",
description: "为检索到的文档给出相关性评分。",
schema: z.object({
binaryScore: z.string().describe("相关性评分 'yes' 或 'no'"),
})
}
const prompt = ChatPromptTemplate.fromTemplate(
`你是一个评估者,负责评估检索到的文档与用户问题的相关性。
以下是检索到的文档:
\n ------- \n
{context}
\n ------- \n
以下是用户问题:{question}
如果文档内容与用户问题相关,请将其评分标记为相关。
给出一个二元评分 'yes' 或 'no',以表明文档是否与问题相关。
Yes:文档与问题相关。
No:文档与问题不相关。`,
);
const model = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
}).bindTools([tool], {
tool_choice: tool.name,
});
const chain = prompt.pipe(model);
const lastMessage = messages[messages.length - 1];
const score = await chain.invoke({
question: messages[0].content as string,
context: lastMessage.content as string,
});
return {
messages: [score]
};
}
/**
* 检查前一次 LLM 工具调用的相关性。
*
* @param {typeof GraphState.State} state - 代理的当前状态,包含所有消息。
* @returns {string} - 基于文档相关性返回 "yes" 或 "no" 的指令。
*/
function checkRelevance(state: typeof GraphState.State): string {
console.log("---检查相关性---");
const { messages } = state;
const lastMessage = messages[messages.length - 1];
if (!("tool_calls" in lastMessage)) {
throw new Error("‘checkRelevance’节点要求最近的消息必须包含工具调用。")
}
const toolCalls = (lastMessage as AIMessage).tool_calls;
if (!toolCalls || !toolCalls.length) {
throw new Error("最后一条消息不是函数消息");
}
if (toolCalls[0].args.binaryScore === "yes") {
console.log("---决策:文档相关---");
return "yes";
}
console.log("---决策:文档不相关---");
return "no";
}
// 节点
/**
* 调用代理模型,根据当前状态生成响应。
* 此函数调用代理模型,以生成对当前对话状态的响应。
* 该响应将被添加到状态的消息列表中。
* @param {typeof GraphState.State} state - 代理的当前状态,包含所有消息。
* @returns {Promise<Partial<typeof GraphState.State>>} - 更新后的状态,新消息已添加到消息列表中。
*/
async function agent(state: typeof GraphState.State): Promise<Partial<typeof GraphState.State>> {
console.log("---调用代理---");
const { messages } = state;
// 查找包含 `give_relevance_score` 工具调用的 AIMessage,
// 如果存在则移除。因为代理不需要知道相关性评分。
const filteredMessages = messages.filter((message) => {
if ("tool_calls" in message && Array.isArray(message.tool_calls) && message.tool_calls.length > 0) {
return message.tool_calls[0].name !== "give_relevance_score";
}
return true;
});
const model = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
streaming: true,
}).bindTools(tools);
const response = await model.invoke(filteredMessages);
return {
messages: [response],
};
}
/**
* 重写查询,以生成更优的问题。
* @param {typeof GraphState.State} state - 代理的当前状态,包含所有消息。
* @returns {Promise<Partial<typeof GraphState.State>>} - 更新后的状态,新消息已添加到消息列表中。
*/
async function rewrite(state: typeof GraphState.State): Promise<Partial<typeof GraphState.State>> {
console.log("---重写查询---");
const { messages } = state;
const question = messages[0].content as string;
const prompt = ChatPromptTemplate.fromTemplate(
`请查看输入内容,并尝试推断其潜在的语义意图/含义。\n
这是初始问题:
\n ------- \n
{question}
\n ------- \n
请重新表述一个更优的问题:`,
);
// 评分器
const model = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
streaming: true,
});
const response = await prompt.pipe(model).invoke({ question });
return {
messages: [response],
};
}
/**
* 生成答案
* @param {typeof GraphState.State} state - 代理的当前状态,包含所有消息。
* @returns {Promise<Partial<typeof GraphState.State>>} - 更新后的状态,新消息已添加到消息列表中。
*/
async function generate(state: typeof GraphState.State): Promise<Partial<typeof GraphState.State>> {
console.log("---生成答案---");
const { messages } = state;
const question = messages[0].content as string;
// 提取最新的 ToolMessage
const lastToolMessage = messages.slice().reverse().find((msg) => msg._getType() === "tool");
if (!lastToolMessage) {
throw new Error("对话历史中未找到工具消息");
}
const docs = lastToolMessage.content as string;
const prompt = await pull<ChatPromptTemplate>("rlm/rag-prompt");
const llm = new ChatOpenAI({
model: "gpt-4o",
temperature: 0,
streaming: true,
});
const ragChain = prompt.pipe(llm);
const response = await ragChain.invoke({
context: docs,
question,
});
return {
messages: [response],
};
}
## 图结构
* 从代理节点 `callModel` 开始
* 代理决定是否调用函数
* 如果是,则执行 `action` 节点调用工具(检索器)
* 然后将工具输出添加到消息中,再次调用代理(`state`)
```typescript
import { StateGraph } from "@langchain/langgraph";
// 定义图结构
const workflow = new StateGraph(GraphState)
// 定义我们将循环使用的节点。
.addNode("agent", agent)
.addNode("retrieve", toolNode)
.addNode("gradeDocuments", gradeDocuments)
.addNode("rewrite", rewrite)
.addNode("generate", generate);
import { START } from "@langchain/langgraph";
// 调用代理节点以决定是否检索
workflow.addEdge(START, "agent");
// 决定是否检索
workflow.addConditionalEdges(
"agent",
// 评估代理的决策
shouldRetrieve,
);
workflow.addEdge("retrieve", "gradeDocuments");
// 在调用 `action` 节点后所采取的边。
workflow.addConditionalEdges(
"gradeDocuments",
// 评估代理决策
checkRelevance,
{
// 调用工具节点
yes: "generate",
no: "rewrite", // 占位符
},
);
workflow.addEdge("generate", END);
workflow.addEdge("rewrite", "agent");
// 编译
const app = workflow.compile();
import { HumanMessage } from "@langchain/core/messages";
const inputs = {
messages: [
new HumanMessage(
"根据 Lilian Weng 的博客文章,智能体记忆有哪些类型?",
),
],
};
let finalState;
for await (const output of await app.stream(inputs)) {
for (const [key, value] of Object.entries(output)) {
const lastMsg = output[key].messages[output[key].messages.length - 1];
console.log(`来自节点: '${key}' 的输出`);
console.dir({
type: lastMsg._getType(),
content: lastMsg.content,
tool_calls: lastMsg.tool_calls,
}, { depth: null });
console.log("---\n");
finalState = value;
}
}
console.log(JSON.stringify(finalState, null, 2));
---调用代理---
---决定检索---
---决策:检索---
来自节点: 'agent' 的输出
{
type: 'ai',
content: '',
tool_calls: [
{
name: 'retrieve_blog_posts',
args: { query: 'types of agent memory' },
id: 'call_adLYkV7T2ry1EZFboT0jPuwn',
type: 'tool_call'
}
]
}
---
来自节点: 'retrieve' 的输出
{
type: 'tool',
content: '智能体系统概述\n' +
' \n' +
' 组件一:规划\n' +
' \n' +
' \n' +
' 任务分解\n' +
' \n' +
' 自我反思\n' +
' \n' +
' \n' +
' 组件二:记忆\n' +
' \n' +
' \n' +
' 记忆类型\n' +
' \n' +
' 最大内积搜索(MIPS)\n' +
'\n' +
'记忆流:是一种长期记忆模块(外部数据库),以自然语言形式记录智能体经验的完整列表。\n' +
'\n' +
'每个元素都是一次观察,即由智能体直接提供的事件。\n' +
'- 智能体间的通信可能触发新的自然语言语句。\n' +
'\n' +
'\n' +
'检索模型:根据相关性、时效性和重要性提取上下文,以指导智能体的行为。\n' +
'\n' +
'规划\n' +
'\n' +
'子目标与分解:智能体将大型任务分解为更小、更易管理的子目标,从而高效处理复杂任务。\n' +
'反思与优化:智能体可对过去的行为进行自我批评和反思,从错误中学习并优化未来步骤,从而提高最终结果的质量。\n' +
'\n' +
'\n' +
'记忆\n' +
'\n' +
'生成式智能体的设计结合了LLM与记忆、规划和反思机制,使智能体能够基于过往经验行动,并与其他智能体交互。',
tool_calls: undefined
}
---
---获取相关性评分---
---检查相关性---
---决策:文档不相关---
来自节点: 'gradeDocuments' 的输出
{
type: 'ai',
content: '',
tool_calls: [
{
name: 'give_relevance_score',
args: { binaryScore: 'no' },
type: 'tool_call',
id: 'call_AGE7gORVFubExfJWcjb0C2nV'
}
]
}
---
---重写查询---
来自节点: 'rewrite' 的输出
{
type: 'ai',
content: "Lilian Weng 的博客文章中描述了哪些不同类型的智能体记忆?",
tool_calls: []
}
---
---调用代理---
---决定检索---
来自节点: 'agent' 的输出
{
type: 'ai',
content: "Lilian Weng 的博客文章描述了以下类型的智能体记忆:\n" +
'\n' +
'1. **记忆流(Memory Stream)**:\n' +
' - 这是一种长期记忆模块(外部数据库),以自然语言形式记录智能体经验的完整列表。\n' +
' - 记忆流中的每个元素都是一次观察或由智能体直接提供的事件。\n' +
' - 智能体间的通信可能触发新的自然语言语句添加到记忆流中。\n' +
'\n' +
'2. **检索模型(Retrieval Model)**:\n' +
' - 该模型根据相关性、时效性和重要性提取上下文,以指导智能体的行为。\n' +
'\n' +
'这些记忆类型是更广泛设计的一部分,该设计将生成式智能体与记忆、规划和反思机制相结合,使智能体能够基于过往经验行动,并与其他智能体交互。',
tool_calls: []
}
---
{
"messages": [
{
"lc": 1,
"type": "constructor",
"id": [
"langchain_core",
"messages",
"AIMessageChunk"
],
"kwargs": {
"content": "Lilian Weng 的博客文章描述了以下类型的智能体记忆:\n\n1. **记忆流(Memory Stream)**:\n - 这是一种长期记忆模块(外部数据库),以自然语言形式记录智能体经验的完整列表。\n - 记忆流中的每个元素都是一次观察或由智能体直接提供的事件。\n - 智能体间的通信可能触发新的自然语言语句添加到记忆流中。\n\n2. **检索模型(Retrieval Model)**:\n - 该模型根据相关性、时效性和重要性提取上下文,以指导智能体的行为。\n\n这些记忆类型是更广泛设计的一部分,该设计将生成式智能体与记忆、规划和反思机制相结合,使智能体能够基于过往经验行动,并与其他智能体交互。",
"additional_kwargs": {},
"response_metadata": {
"estimatedTokenUsage": {
"promptTokens": 280,
"completionTokens": 155,
"totalTokens": 435
},
"prompt": 0,
"completion": 0,
"finish_reason": "stop",
"system_fingerprint": "fp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8b62c3bfp_3cd8......(省略重复指纹)"
},
"tool_call_chunks": [],
"id": "chatcmpl-9zAaVQGmTLiCaFvtbxUK60qMFsSmU",
"usage_metadata": {
"input_tokens": 363,
"output_tokens": 156,
"total_tokens": 519
},
"tool_calls": [],
"invalid_tool_calls": []
}
}
]
}