概览
典型的 RAG 应用包含两个主要组件: 索引构建:从数据源摄取数据并建立索引的流水线。该过程通常在独立进程中完成。 检索与生成:实际的 RAG 过程,在运行时接收用户查询,从索引中检索相关数据,再将其传递给模型生成答案。 完成数据索引后,我们将使用 代理 作为编排框架,实现检索与生成步骤。环境设置
安装
本教程需要以下 LangChain 依赖项:LangSmith
使用 LangChain 构建的许多应用都包含多个步骤及多次 LLM 调用。随着应用复杂度增加,能够检查链或代理内部具体运行情况变得至关重要。最佳方式是使用 LangSmith。 注册上述链接后,请设置环境变量以开始记录追踪:组件选择
我们需要从 LangChain 的集成套件中选择三个组件: 选择聊天模型:- OpenAI
- Anthropic
- Azure
- Google Gemini
- AWS Bedrock
- OpenAI
- Azure
- Google Gemini
- Google Vertex
- AWS
- HuggingFace
- Ollama
- Cohere
- MistralAI
- Nomic
- NVIDIA
- Voyage AI
- IBM watsonx
- Fake
- In-memory
- AstraDB
- Chroma
- FAISS
- Milvus
- MongoDB
- PGVector
- PGVectorStore
- Pinecone
- Qdrant
预览
本指南将构建一个可回答网站内容相关问题的应用。我们将使用的具体网站是 Lilian Weng 的博客文章《LLM 驱动的自主代理》,从而可针对该文章内容提问。 我们仅需约 40 行代码即可创建一个简单的索引流水线和 RAG 链。完整代码片段如下:展开查看完整代码片段
展开查看完整代码片段
详细分步讲解
接下来,我们将逐步解析上述代码,深入理解其工作原理。1. 索引构建
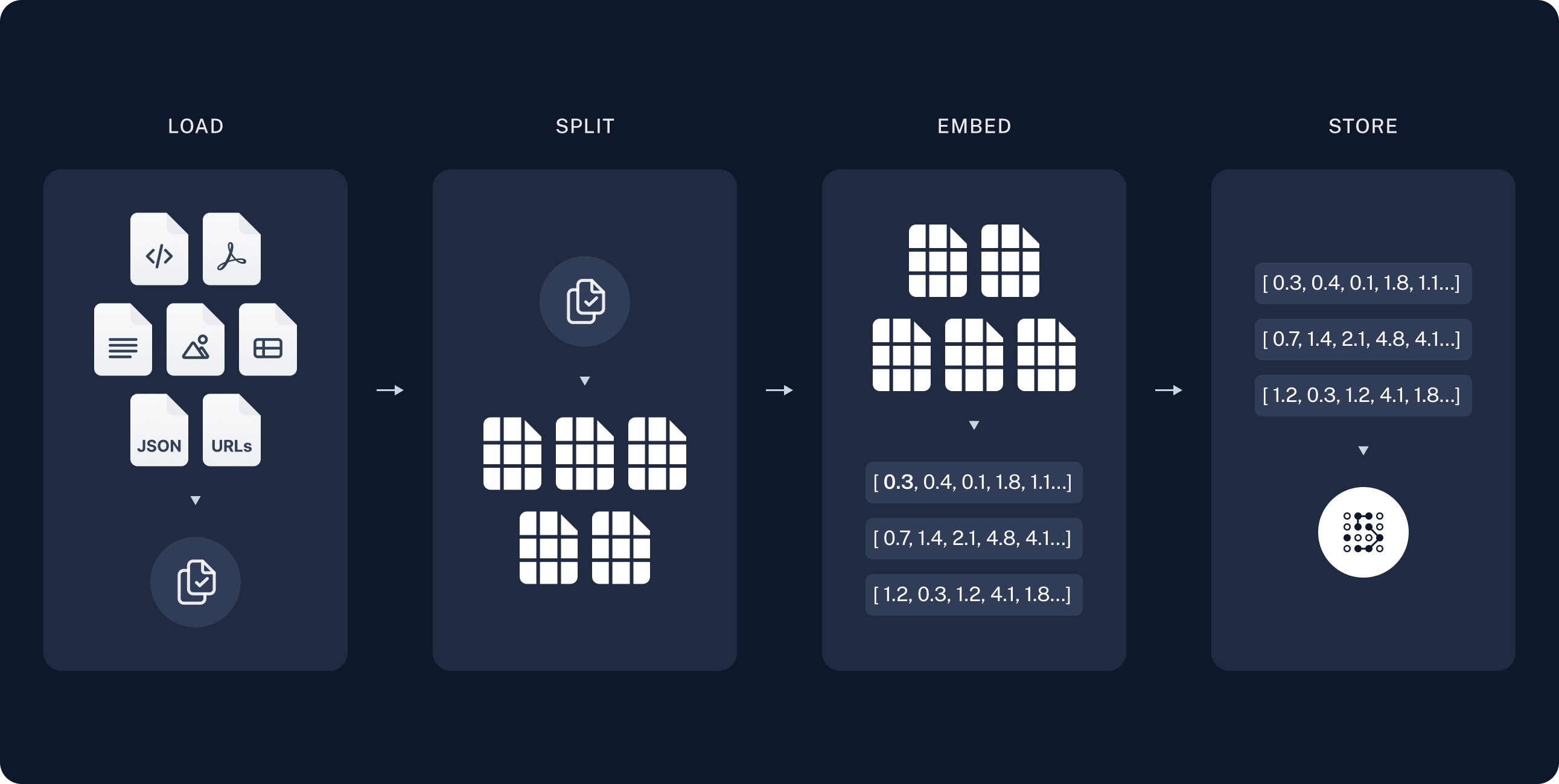
索引构建通常包含以下步骤:- 加载:首先需要加载数据,这通过 文档加载器 完成。
- 分块:文本分块器 将大型
文档拆分为更小的块。这对数据索引和模型输入均有帮助,因为大块数据更难搜索,且无法适配模型有限的上下文窗口。 - 存储:我们需要存储并索引这些分块,以便后续检索。这通常使用 向量数据库 和 嵌入模型 实现。
{kind=link}
加载文档
首先需要加载博客文章内容。我们可以使用 文档加载器,这些对象从数据源加载数据并返回 文档 对象列表。 此处我们将使用 WebBaseLoader,它利用urllib 从网页 URL 加载 HTML,并使用 BeautifulSoup 解析为文本。我们可通过 bs_kwargs 参数自定义 HTML -> 文本解析(参见 BeautifulSoup 文档)。本例中仅需保留 class 为 “post-content”、“post-title” 或 “post-header” 的 HTML 标签,因此移除其他所有标签。
文档加载器:从数据源加载数据并返回 文档 对象列表的对象。
文档分块
我们加载的文档超过 42,000 字符,对于许多模型而言过长,无法适配其上下文窗口。即使部分模型可容纳整篇文章,它们在很长的输入中也难以有效查找信息。 为此,我们将文档 分块以便嵌入和向量存储。这有助于在运行时仅检索文章中最相关的部分。
如 语义搜索教程 所述,我们使用 RecursiveCharacterTextSplitter,它会递归地使用常见分隔符(如换行符)拆分文档,直至每个块达到合适大小。这是通用文本用例推荐的文本分块器。
文本分块器:将 文档 对象列表拆分为更小块的对象,用于存储和检索。
存储文档
现在我们需要对 66 个文本块建立索引,以便在运行时进行搜索。遵循 语义搜索教程,我们的方法是 嵌入 每个文档块的内容,并将这些嵌入向量插入 向量数据库。给定用户查询时,即可使用向量搜索检索相关文档。 我们可在单条命令中完成所有文档块的嵌入和存储,使用教程 开头选定的向量数据库和嵌入模型。嵌入模型:文本嵌入模型的封装,用于将文本转换为嵌入向量。
向量数据库:向量数据库的封装,用于存储和查询嵌入向量。
至此,流水线的 索引构建 部分已完成。此时我们已拥有一个可查询的向量数据库,其中包含博客文章的分块内容。给定用户问题,我们应能返回回答该问题的文章片段。
2. 检索与生成
RAG 应用通常按以下步骤工作: retrieval_diagram 现在,我们来编写实际的应用逻辑。我们希望创建一个简单应用,接收用户问题,搜索与该问题相关的文档,将检索到的文档和初始问题传递给模型,并返回答案。 我们将演示: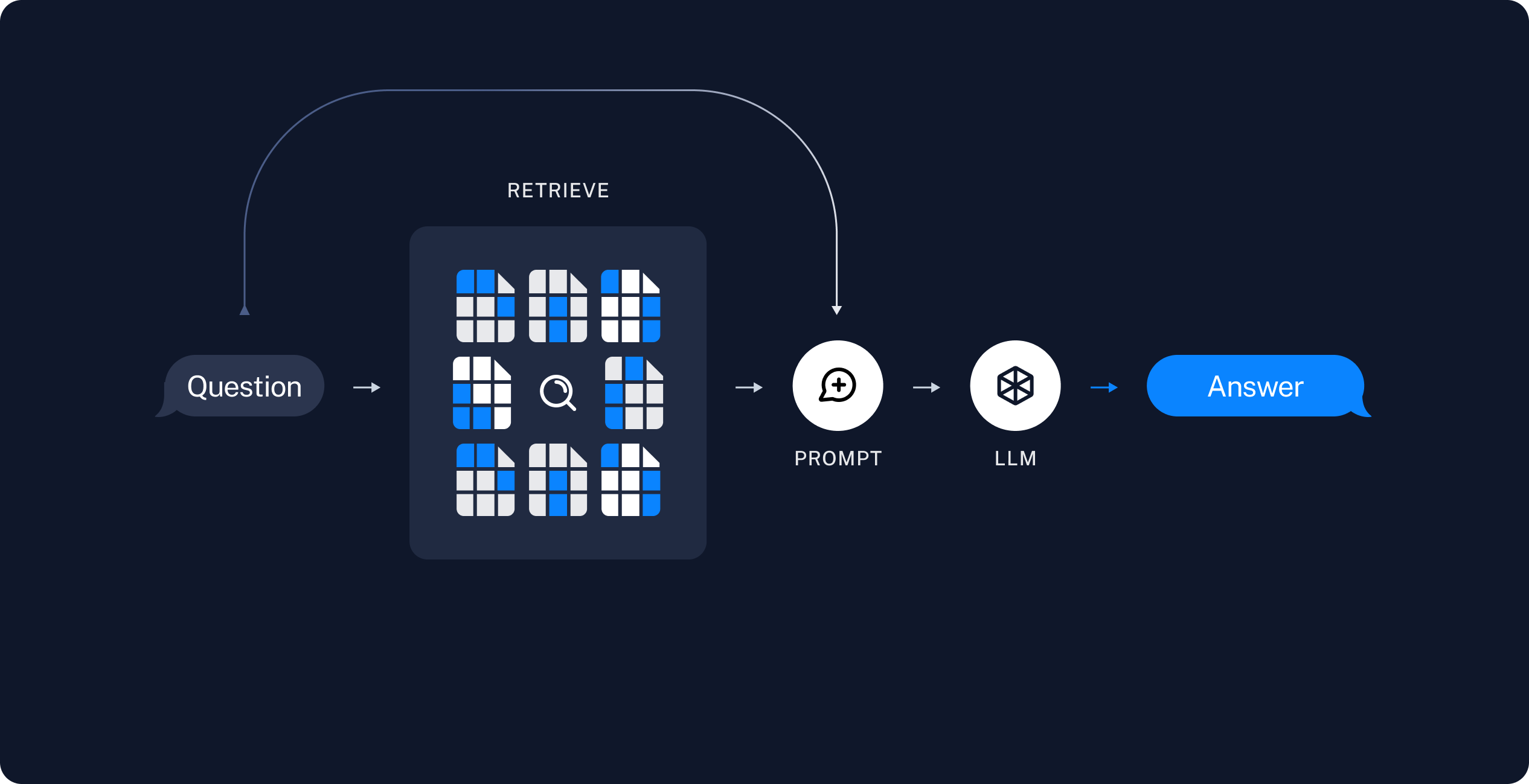{kind=link}
RAG 代理
一种 RAG 应用的实现方式是将其构建为一个简单的代理,并配备一个用于检索信息的工具。我们可以通过实现一个封装向量存储的工具,来组装一个最小化的 RAG 代理:- 生成一个查询,用于搜索任务分解的标准方法;
- 收到答案后,生成第二个查询,用于搜索该方法的常见扩展;
- 在获取所有必要上下文后,最终回答问题。
RAG 链
在上述 代理式 RAG 实现中,我们允许 LLM 自主决定是否生成 工具调用 以帮助回答用户查询。这是一种通用性较强的解决方案,但也存在一些权衡:
另一种常见的方法是两步链,即我们始终执行一次搜索(可能使用原始用户查询),并将结果作为上下文整合到单次 LLM 查询中。这种方法每次查询仅需一次推理调用,在牺牲灵活性的同时降低了延迟。
在这种方法中,我们不再循环调用模型,而是仅执行单次传递。我们可以通过从代理中移除工具,并将检索步骤整合到自定义提示中来实现这一链式结构:
返回源文档
返回源文档
后续步骤
现在我们已经通过create_agent 实现了一个简单的 RAG 应用,可以轻松集成新功能并深入探索:
- 流式传输 令牌和其他信息,以提供响应迅速的用户体验
- 添加 对话记忆,以支持多轮交互
- 添加 长期记忆,以支持跨对话线程的记忆
- 添加 结构化响应
- 使用 LangGraph 平台 部署你的应用